Games Animation Forum
~清談館~>AI 人工智能 (AlphaZero制霸圍棋、西洋棋、日本將棋)
歌絲˙暮斯 10:01 PM 08-04-17
作者: Rance:
大陸AI同提款機一樣入面有個人坐O係度O者
大陸AI同提款機一樣入面有個人坐O係度O者
由手機版發出
( ゚ω゚)? 09:46 PM 10-19-17
AlphaGo 零式 ,以經超越人類
,以經超越人類
https://unwire.hk/2017/10/19/alphago-zero/life-tech/
新 AlphaGo Zero 自學 21 日擊敗上代 AlphaGo 不靠人類知識
讚好此文:
十月 19, 2017 •生活科技 •
Google 系列企業 DeepMind 開發的 AlphaGo 圍棋 AI 系統,在人機對戰贏了中國棋手柯潔之後退役。不過 DeepMind 已經準備好用全新技術製作的「AlphaGo Zero」AI 系統,最大的進化是它毋須學習人類對弈,僅透過自我強化學習的演算法,就能學成精通的圍棋技藝。

以往的 AlphaGo 學習圍棋,使用了大量人類圍棋對局的資料進行學習,另外再加上自我對弈以加強學習效果。但今次 DeepMind 在科學雜誌《Nature》就發表了題為《Mastering the game of Go without human knowledge》(毋須人類智識就能掌握圍棋)的論文。當中提到了進化版的「AlphaGo Zero」人工智能系統,可以只單靠自我學習來達到掌握圍棋技藝。
在全新技術當中,AlphaGo Zero 神經網絡從一塊連圍棋規則也不知道的「白板」開始,技術人員再將這個網絡跟搜尋演算法結合,然後就開始了自我學習。AI 人工智能系統不斷進行自我對弈,把自己的下棋方法加以學習、改進,不斷增強下棋的判定。它只從一塊「白板」開始學習,用了 3 天的時間,就達到了他的上兩代「AlphaGo Lee」(擊敗棋手李世乭的系統),而只利用了 21 日的時間,就達到了他的上一代「AlphaGo Master」(擊敗柯潔的系統)相同的水準。
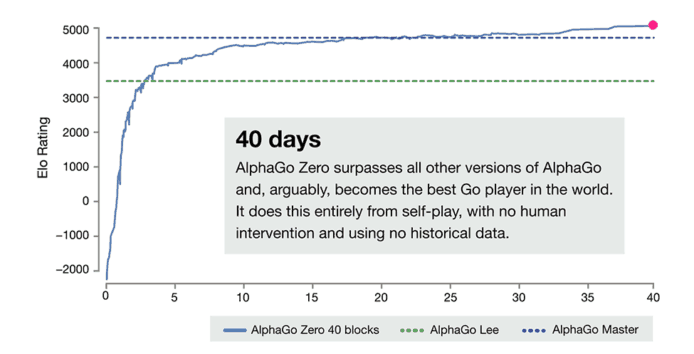
從開始就能自我學習的 AlphaGo Zero,厲害之處除了靠自我學習就得到了人類長久以來累積的圍棋策略經驗之外,更獲得了一些人類棋手未知的策略技術。AlphaGo Zero 系統只用了 40 日,就成為了世界最強的圍棋棋手。
資料來源:YouTube, Google, NPR
,以經超越人類https://unwire.hk/2017/10/19/alphago-zero/life-tech/
新 AlphaGo Zero 自學 21 日擊敗上代 AlphaGo 不靠人類知識
讚好此文:
十月 19, 2017 •生活科技 •
Google 系列企業 DeepMind 開發的 AlphaGo 圍棋 AI 系統,在人機對戰贏了中國棋手柯潔之後退役。不過 DeepMind 已經準備好用全新技術製作的「AlphaGo Zero」AI 系統,最大的進化是它毋須學習人類對弈,僅透過自我強化學習的演算法,就能學成精通的圍棋技藝。
以往的 AlphaGo 學習圍棋,使用了大量人類圍棋對局的資料進行學習,另外再加上自我對弈以加強學習效果。但今次 DeepMind 在科學雜誌《Nature》就發表了題為《Mastering the game of Go without human knowledge》(毋須人類智識就能掌握圍棋)的論文。當中提到了進化版的「AlphaGo Zero」人工智能系統,可以只單靠自我學習來達到掌握圍棋技藝。
在全新技術當中,AlphaGo Zero 神經網絡從一塊連圍棋規則也不知道的「白板」開始,技術人員再將這個網絡跟搜尋演算法結合,然後就開始了自我學習。AI 人工智能系統不斷進行自我對弈,把自己的下棋方法加以學習、改進,不斷增強下棋的判定。它只從一塊「白板」開始學習,用了 3 天的時間,就達到了他的上兩代「AlphaGo Lee」(擊敗棋手李世乭的系統),而只利用了 21 日的時間,就達到了他的上一代「AlphaGo Master」(擊敗柯潔的系統)相同的水準。
從開始就能自我學習的 AlphaGo Zero,厲害之處除了靠自我學習就得到了人類長久以來累積的圍棋策略經驗之外,更獲得了一些人類棋手未知的策略技術。AlphaGo Zero 系統只用了 40 日,就成為了世界最強的圍棋棋手。
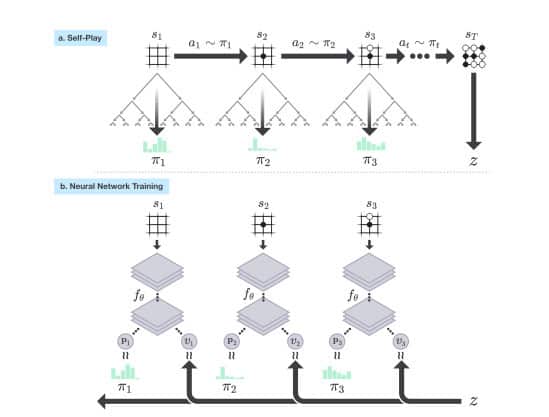
▲AlphaGo Zero的自我學習流程
深度學習需要有大量資料輔助,例如以前 AlphaGo 需要的對局資料,有時候資料的成本高昂,而且知識有時也未必輕易得到。AlphaGo Zero 這項技術突破,日後可利用於解決人類未曾認識的重大挑戰。資料來源:YouTube, Google, NPR
大覺屋師真 11:18 AM 10-20-17
天網:人類已經無存在價值了")
真!DC 01:28 PM 10-20-17
發明左車味一樣有賽跑運動員
由手機版發出
由手機版發出
D.K. 02:44 PM 10-20-17
二課同英格倫1號已經證明左 零式唔係最好
12號四分衛 02:52 PM 10-20-17
歌絲˙暮斯 02:56 PM 10-20-17
Patlabor 電影 0 式既 neuron network 概念,現實起 80-90 年代已經有。
唔係咩高科技。
Labour 既基礎,超傳導馬達就仲未有。
由手機版發出
唔係咩高科技。
Labour 既基礎,超傳導馬達就仲未有。
由手機版發出
真!DC 02:57 PM 10-20-17
人類走去擔心會不會被取代而唔係諗點樣有效利用好可悲
由手機版發出
由手機版發出
( ゚ω゚)? 11:26 AM 04-28-18
有造假成份
https://hk.news.appledaily.com/inter...80428/20375340
曾敗給AlphaGo 中國棋王食言再鬥電腦
苦戰國產AI 柯潔落敗
 ■中國圍棋棋王柯潔力戰AI星陣圍棋,最終不敵落敗。路透社
■中國圍棋棋王柯潔力戰AI星陣圍棋,最終不敵落敗。路透社
去年含淚慘敗給人工智能AlphaGo的中國圍棋棋王、世界排名第二柯潔,昨打破此前拒絕再戰AI承諾,與中國自行開發的AI系統星陣圍棋(Golaxy)對弈。雙方酣戰2小時,柯潔到中盤主動投子認輸,再次敗於人工智能圍棋程式。棋王再戰AI備受矚目,在網上觀戰的香港業餘六段、七屆全港圍棋冠軍陳乃申向《蘋果》記者表示,柯潔輸在無法保持平常心,也未發揮應有水準。
柯潔昨在福建福州挑戰圍棋AI星陣圍棋,這場人機大戰屬表演賽,只有一局,勝出的話可獲獎金100萬人民幣(約125萬港元),比賽按中國圍棋規則進行。柯潔有別於以往一貫的張揚及自信,在賽前自稱對星陣勝算僅10-20%,在微博也未提再戰AI的感受。對戰昨午2時半開始,星陣執黑子先行,柯潔執白子,事實上柯執白往績勝率較高,他選擇「宇宙流」(着重外勢的圍棋佈局)開局,雙方很快形成白棋取實地黑棋獲外勢的格局。柯潔攻殺黑棋堅決,經過將近30手絲毫不落下風,局面更佔優勢,甚至逼得星陣一度陷入長思。但星陣下得靈活,在一輪攻守下,黑棋一路連追帶打,逼得柯潔的白棋右上和中央不能兩全。

酣戰2小時認輸
當白棋右上兩子被鯨吞,柯潔局勢變得被動。內媒即時評論形容:「AI下棋總是簡單而粗暴,短平快、穩準狠。」到比賽中段,受星陣輕靈飄忽的棋法影響,柯潔不時凝神沉思,局勢不利之下,柯潔做出一個劫爭(圍棋步法之一),星陣未讓柯潔計謀得逞。眼見絕殺無望,柯潔頻頻嘆氣搖頭,在直播畫面中更一直揪住自己頭髮,戰至145手柯潔無以為繼,雙方大戰2小時20分鐘後,柯只能投子認輸。
中國圍棋協會主席林建超大讚柯潔的表現,又指在人與AI棋弈之間,人的勇氣尤其重要,柯潔雖自知有差距,但仍決定接受挑戰是「精神上的飛躍」。內地評論指,星陣開局不久已佔優勢,在30手後星陣顯示黑棋勝率超過60%,隨後勝率升至70%以上,最終迫使柯潔投子認輸。
柯未發揮水準
香港業餘六段、七屆全港圍棋冠軍陳乃申觀看柯星對戰後,並向《蘋果》記者表示,賽事僅花約2小時已分勝負,比起職業賽事動輒6小時的作賽時間,時間較短。陳指,星陣分析出60手已出現敗着(圍棋術語,因一步錯誤棋步而導致輸棋)。柯潔在早期已出現敗勢,認為柯對戰電腦時無法保持平常心,未有發揮應有水準,導致迅速敗陣。
陳乃申還比較AlphaGo與星陣的「戰力」,指AlphaGo的棋法連專業棋手也難以看懂,星陣棋法則可用人類思維理解,棋法比AlphaGo接近人類,他認為,專業棋手能下得出星陣的棋法,感覺AlphaGo略勝一籌,但仍要經對陣才能分高低。
記者廖智廣
https://hk.news.appledaily.com/inter...80428/20375340
曾敗給AlphaGo 中國棋王食言再鬥電腦
苦戰國產AI 柯潔落敗
| | |
 ■中國圍棋棋王柯潔力戰AI星陣圍棋,最終不敵落敗。路透社
■中國圍棋棋王柯潔力戰AI星陣圍棋,最終不敵落敗。路透社 去年含淚慘敗給人工智能AlphaGo的中國圍棋棋王、世界排名第二柯潔,昨打破此前拒絕再戰AI承諾,與中國自行開發的AI系統星陣圍棋(Golaxy)對弈。雙方酣戰2小時,柯潔到中盤主動投子認輸,再次敗於人工智能圍棋程式。棋王再戰AI備受矚目,在網上觀戰的香港業餘六段、七屆全港圍棋冠軍陳乃申向《蘋果》記者表示,柯潔輸在無法保持平常心,也未發揮應有水準。
柯潔昨在福建福州挑戰圍棋AI星陣圍棋,這場人機大戰屬表演賽,只有一局,勝出的話可獲獎金100萬人民幣(約125萬港元),比賽按中國圍棋規則進行。柯潔有別於以往一貫的張揚及自信,在賽前自稱對星陣勝算僅10-20%,在微博也未提再戰AI的感受。對戰昨午2時半開始,星陣執黑子先行,柯潔執白子,事實上柯執白往績勝率較高,他選擇「宇宙流」(着重外勢的圍棋佈局)開局,雙方很快形成白棋取實地黑棋獲外勢的格局。柯潔攻殺黑棋堅決,經過將近30手絲毫不落下風,局面更佔優勢,甚至逼得星陣一度陷入長思。但星陣下得靈活,在一輪攻守下,黑棋一路連追帶打,逼得柯潔的白棋右上和中央不能兩全。

酣戰2小時認輸
當白棋右上兩子被鯨吞,柯潔局勢變得被動。內媒即時評論形容:「AI下棋總是簡單而粗暴,短平快、穩準狠。」到比賽中段,受星陣輕靈飄忽的棋法影響,柯潔不時凝神沉思,局勢不利之下,柯潔做出一個劫爭(圍棋步法之一),星陣未讓柯潔計謀得逞。眼見絕殺無望,柯潔頻頻嘆氣搖頭,在直播畫面中更一直揪住自己頭髮,戰至145手柯潔無以為繼,雙方大戰2小時20分鐘後,柯只能投子認輸。
中國圍棋協會主席林建超大讚柯潔的表現,又指在人與AI棋弈之間,人的勇氣尤其重要,柯潔雖自知有差距,但仍決定接受挑戰是「精神上的飛躍」。內地評論指,星陣開局不久已佔優勢,在30手後星陣顯示黑棋勝率超過60%,隨後勝率升至70%以上,最終迫使柯潔投子認輸。
柯未發揮水準
香港業餘六段、七屆全港圍棋冠軍陳乃申觀看柯星對戰後,並向《蘋果》記者表示,賽事僅花約2小時已分勝負,比起職業賽事動輒6小時的作賽時間,時間較短。陳指,星陣分析出60手已出現敗着(圍棋術語,因一步錯誤棋步而導致輸棋)。柯潔在早期已出現敗勢,認為柯對戰電腦時無法保持平常心,未有發揮應有水準,導致迅速敗陣。
陳乃申還比較AlphaGo與星陣的「戰力」,指AlphaGo的棋法連專業棋手也難以看懂,星陣棋法則可用人類思維理解,棋法比AlphaGo接近人類,他認為,專業棋手能下得出星陣的棋法,感覺AlphaGo略勝一籌,但仍要經對陣才能分高低。
記者廖智廣
martinnitram 04:14 PM 04-28-18
作者: ( ゚ω゚)?:
有造假成份
不如直接挑 AlphaGo 機...有造假成份
歌絲˙暮斯 04:21 PM 04-28-18
你的國出產既 AI 你自己都打唔贏.....
由手機版發出
由手機版發出
亍 ◣ 05:23 PM 04-28-18
不遲不早,呢個時間出戰比"我的國"AI打敗?
?
LTKS 12:50 PM 12-09-18
http://udn.com/news/story/7086/3524479
作者: :
去年度,DeepMind打敗自己的紀錄,AlphaGo Zero戰勝首個人類圍棋世界冠軍的程式AlphaGo,當時在Nature這篇論文《Mastering the game of Go without human knowledge》(不使用人類知識制霸圍棋)引起AI界歡聲雷動。今日,DeepMind AlphaGo幕後重要推手黃士傑博士又於臉書上宣布一項振奮人心的消息,新一代 AlphaZero精通自學精通三種棋類,同時團隊也登上了《科學》期刊!
根據DeepMind部落格,經過全面完整的評估AlphaZero被科學界授予更高的肯定,同時也整理Alpha Zero一路以來的戰績。
AlphaGo Zero在於無需任何人類指導,透過全新的強化學習方式,讓AI自己成為自己的老師,更在圍棋這項具挑戰性的領域超越人類水準,相比起之前使用人類對弈的數據,新的演算法訓練時間更短,當時僅用3天時間就達到了擊敗李世乭的AlphaGo Lee的水準,21天就達到了之前擊敗柯潔的AlphaGo Master的水準。
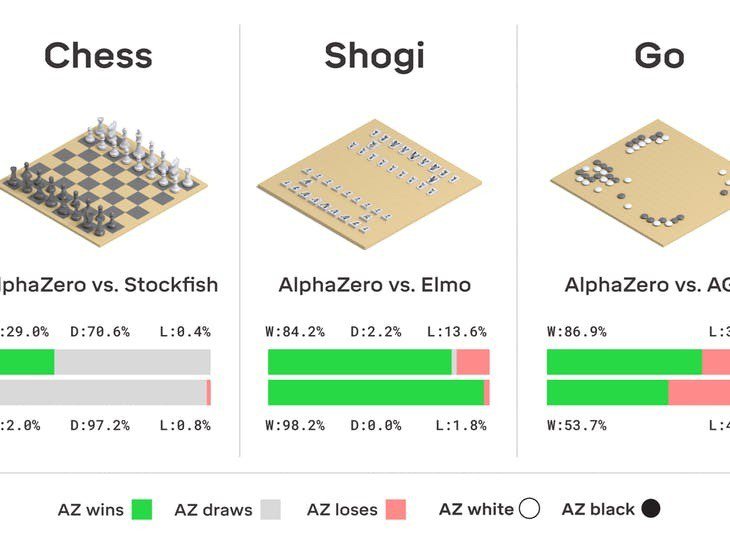
先前AlphaGo Zero是針對圍棋所設計,目前新一代的AlphaZero透過強化學習的方式,再學會三種棋類遊戲:西洋棋(chess)、日本將棋(shogi)與圍棋(Go),AlphaZero藉由強大運算能力-5,000 TPU相當於一台非常大的超級電腦,很快就學會三種棋盤遊戲。不但打贏了前代AlphaGo Zero,在西洋棋甚至大幅超越過去頂尖的傳統西洋棋程式Stockfish (1000局的比數是155勝6敗,而Stockfish遠超1997年戰勝世界冠軍IBM的Deep Blue深藍)。
從電腦時代開始以來,包括Babbage,Turing,Shannon等早期開發者都曾試圖設計西洋棋程式,AlphaZero 突破人工智慧一直以來面臨的巨大挑戰。AlphaZero在人類棋史上寫下嶄新的一頁,就連世界西洋棋冠軍加里卡斯帕羅夫對這樣顛覆人類智慧的AlphaZero讚,然而AlphaZero不單只是讓增加了幾個世紀來玩家對西洋棋、日本將棋、圍棋戰略的思考模式,對人工智慧發展更是新里程碑,更為解決現實問題的智慧系統打下基石。
棋類根本已經無得同大數據庫玩去年度,DeepMind打敗自己的紀錄,AlphaGo Zero戰勝首個人類圍棋世界冠軍的程式AlphaGo,當時在Nature這篇論文《Mastering the game of Go without human knowledge》(不使用人類知識制霸圍棋)引起AI界歡聲雷動。今日,DeepMind AlphaGo幕後重要推手黃士傑博士又於臉書上宣布一項振奮人心的消息,新一代 AlphaZero精通自學精通三種棋類,同時團隊也登上了《科學》期刊!
根據DeepMind部落格,經過全面完整的評估AlphaZero被科學界授予更高的肯定,同時也整理Alpha Zero一路以來的戰績。
AlphaGo Zero在於無需任何人類指導,透過全新的強化學習方式,讓AI自己成為自己的老師,更在圍棋這項具挑戰性的領域超越人類水準,相比起之前使用人類對弈的數據,新的演算法訓練時間更短,當時僅用3天時間就達到了擊敗李世乭的AlphaGo Lee的水準,21天就達到了之前擊敗柯潔的AlphaGo Master的水準。
先前AlphaGo Zero是針對圍棋所設計,目前新一代的AlphaZero透過強化學習的方式,再學會三種棋類遊戲:西洋棋(chess)、日本將棋(shogi)與圍棋(Go),AlphaZero藉由強大運算能力-5,000 TPU相當於一台非常大的超級電腦,很快就學會三種棋盤遊戲。不但打贏了前代AlphaGo Zero,在西洋棋甚至大幅超越過去頂尖的傳統西洋棋程式Stockfish (1000局的比數是155勝6敗,而Stockfish遠超1997年戰勝世界冠軍IBM的Deep Blue深藍)。
從電腦時代開始以來,包括Babbage,Turing,Shannon等早期開發者都曾試圖設計西洋棋程式,AlphaZero 突破人工智慧一直以來面臨的巨大挑戰。AlphaZero在人類棋史上寫下嶄新的一頁,就連世界西洋棋冠軍加里卡斯帕羅夫對這樣顛覆人類智慧的AlphaZero讚,然而AlphaZero不單只是讓增加了幾個世紀來玩家對西洋棋、日本將棋、圍棋戰略的思考模式,對人工智慧發展更是新里程碑,更為解決現實問題的智慧系統打下基石。
ra2hk 01:13 AM 12-10-18
安安 06:01 PM 02-12-19
https://technews.tw/2019/02/12/ibm-ai-debate/
IBM 人工智慧辯論系統挑戰人類 打成平手
IBM 人工智慧辯論系統挑戰人類 打成平手
作者: :
關於 Project Debater 的操作,IBM 研究人員使用報刊雜誌、維基百科和其他來源的大數據內容訓練。
一向位居 IBM 人工智慧架構核心的 Watson,在本次辯論會負責把語音轉成文字。
這項辯論賽是繼圍棋賽和競技遊戲等特別計畫之後,人類與人工智慧的最新對戰領域,
因此也受到科技界的重視。
關於 Project Debater 的操作,IBM 研究人員使用報刊雜誌、維基百科和其他來源的大數據內容訓練。
一向位居 IBM 人工智慧架構核心的 Watson,在本次辯論會負責把語音轉成文字。
這項辯論賽是繼圍棋賽和競技遊戲等特別計畫之後,人類與人工智慧的最新對戰領域,
因此也受到科技界的重視。